-
Hash Table과 array 차이점, 설명영상, 글 요약 2023. 1. 3. 00:01
#1 서론
어떤 사람이 좋아하는 국가들이 배열에 저장되어있다고 가정하자.
그럼 어떤사람이 '한국'을 좋아하는지 찾으려고 한다면 선형검색(Linear Search)을 해서 찾아야 할 것이다.
그럼 시간 복잡도는 O(n)일 것이다.
이것은 그리 효율적이지 않다.
이보다 더 효율적으로 만들 수 있다. 그것을 알아본다.
#1-1 시작하기 전 알아야 할 것
- Hash Table
- Key : Value 형태로 이루어진 자료구조
- 예시
- Python - Dictionary
- JS - Object
- 보통 시간복잡도는 O(1)이지만, 항상 그런것은 아니다. 이유는 Hash function에서 설명한다.
- Hash function
- 아래 그림1과 같이 key를 받아서 일정한 알고리즘을 거친 뒤 인덱스로 변환하여 데이터 배열에 저장한다.
- 하지만, 일정한 알고리즘을 거친 뒤에 변환된 인덱스가 같다면, 그림 2와 같이 그 인덱스 안에 새로운 배열에 두 개 이상의 데이터가 저장되게 된다.
- 인덱스 안에 두개 이상의 데이터가 있으면, 선형검색을 통해 원하는 데이터를 찾는다.
- 그러므로 항상 시간 복잡도가 O(1)은 아니다.
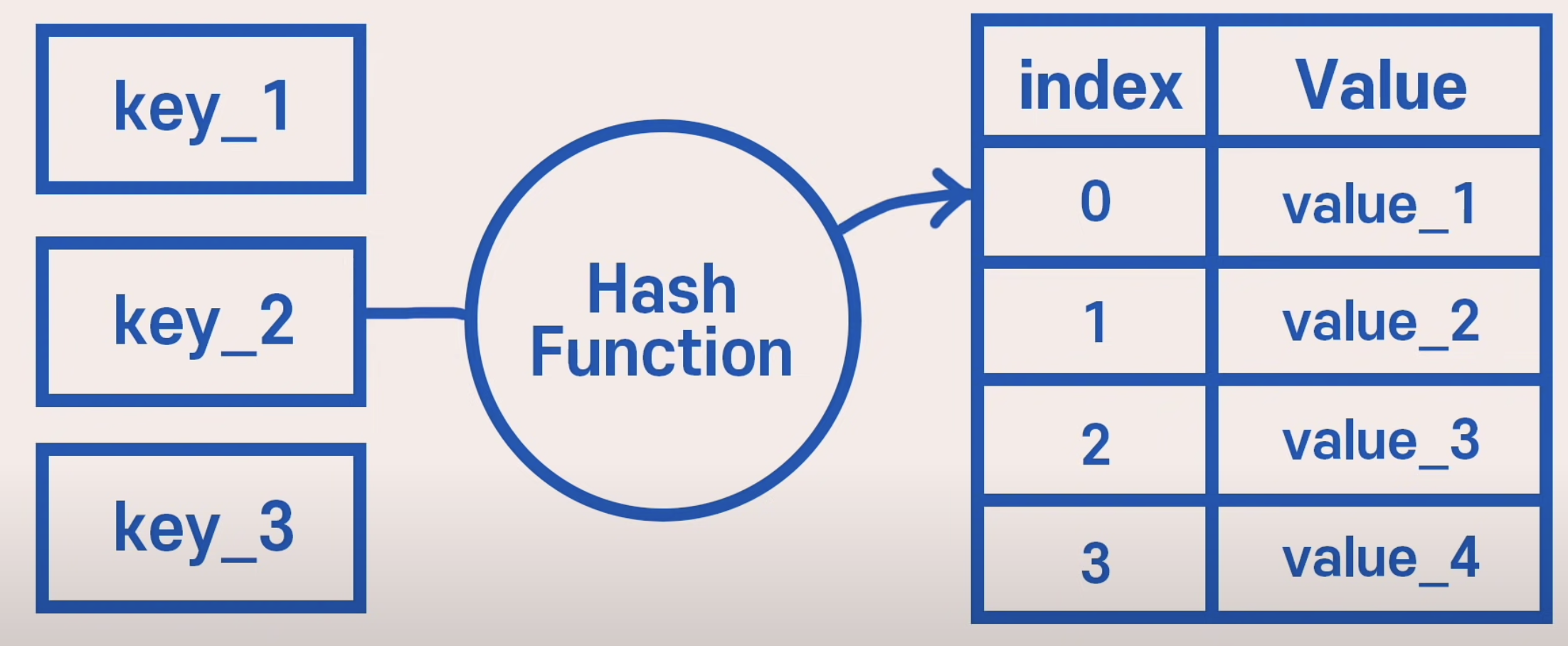
그림 1 
그림2 #2 본론
배열로 저장되어있던 좋아하는 국가들 데이터를 Hash Table로 나타내면 이런 모양일 것이다.
country = { "🇰🇷": true, "🇭🇷": true, "🇦🇷": true, "🇫🇷": true, "🇺🇸": true, "🇬🇭": true, }그럼 좋아하는 나라에 '한국' 이 있는지 찾으려면 아래와 같이 할 수 있다.
contry[🇰🇷] # = true contry[🇷🇺] # = Null#3 결론
이렇게 Hash Table을 사용하면 배열에서 걸린 O(n)대신 O(1)으로 바꿀 수 있다.
#4 참고자료
니꼴라스님 감사합니다
'영상, 글 요약' 카테고리의 다른 글
정적배열, 동적배열 차이점 설명 (0) 2023.01.17 큐(Queues)와 스택(Stacks) (0) 2023.01.04 계수정렬(counting sort)의 원리 (0) 2023.01.01 big O 간단한 설명 (0) 2022.12.26 array(배열) 기초 개념 (0) 2022.12.25 - Hash Table